首个科学计算基座大模型-BBT-Neutron-开源-突破大科学装置数据分析瓶颈
大语言模型能否解决传统大语言模型在大规模数值数据分析中的局限性,帮助科学界在高能物理领域进行大型科学装置的设计和科学计算?

高能物理是探索宇宙基本组成和规律的前沿科学领域。研究极高能量下粒子的相互作用是揭示宇宙起源、暗物质和暗能量等未解之谜的重要手段。
高能物理实验(如粒子碰撞实验、暗物质和暗能量实验等)产生的数据量极其庞大且复杂。传统的数据分析方法在处理海量数据和复杂物理结构时面临计算瓶颈。
最近,arXiv 上更新了一篇名为Scaling Particle Collision Data Analysis 的论文。其中,研究人员从粒子碰撞实验出发,探索大语言模型在大型科学设备的数据分析和科学计算领域的新应用场景——
具体来说,该团队将其新开发的大型科学基础模型BBT-Neutron应用于粒子碰撞实验。该模型采用了新的二值标记化方法,可以实现多模态数据(包括大规模数值实验数据、文本和图像数据)混合预训练。

论文链接:https://arxiv.org/abs/2412.00129 代码地址:https://github.com/supersymmetry-technologies/bbt-neutron 论文将BBT-Neutron 的通用架构模型与最先进的专业JoI 模型(如ParticleNet 和Particle Transformer)进行了比较粒子物理领域射流起源识别(JoI)分类任务的实验结果。
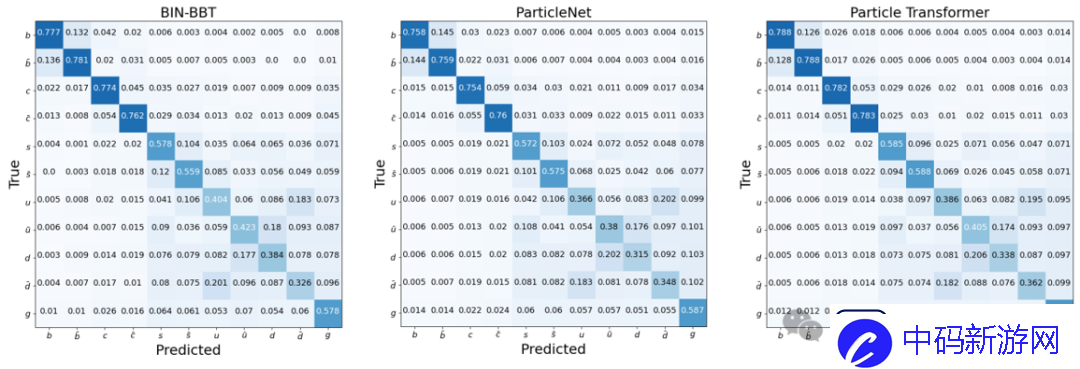
粒子分类的识别精度(图1-3)表明,研究表明这种通用架构的性能与专业模型不相上下,这也验证了基于序列到序列建模的仅解码器架构的能力在学习物理定律的过程中。
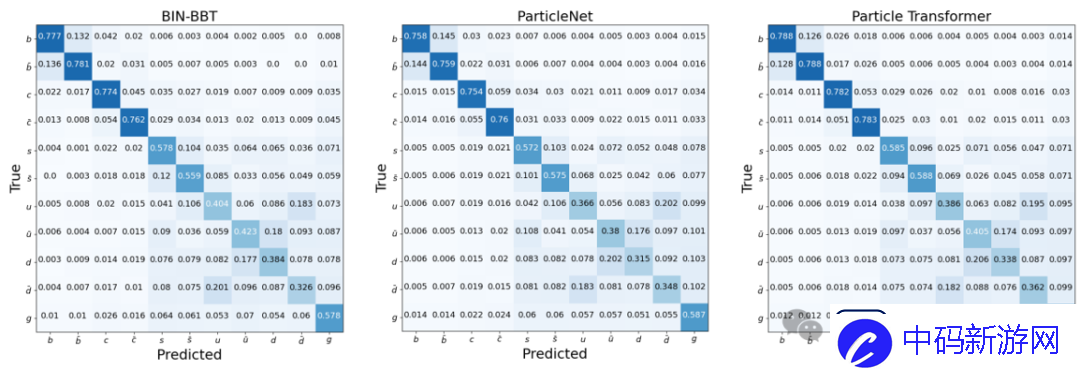
图1:BBT-Neutron模型对11种粒子注入源的识别结果-超对称技术团队图2:ParticleNet模型对11种粒子注入源的识别结果-论文合作者,ParticleNet开发团队(高能所)阮曼琪团队)提供图3:Particle Transformer模型中11种粒子注入源的识别结果——论文合作者,Particle Transformer开发团队(CERN曲惠林团队)提供的这些模型在数据集大小扩展时都显示出性能改进。喷射风味标记效率、电荷翻转率形成S曲线。
然而,在BBT-Neutron 和专业模型之间观察到了不同的缩放行为,并且S 曲线上的关键数据阈值表明BBT-Neutron 中出现了紧急现象(在专业架构中没有看到),这不仅打破了传统信念表明该架构不适合连续物理特征建模的局限性,同时也验证了通用模型在大规模科学计算任务中的可扩展性。
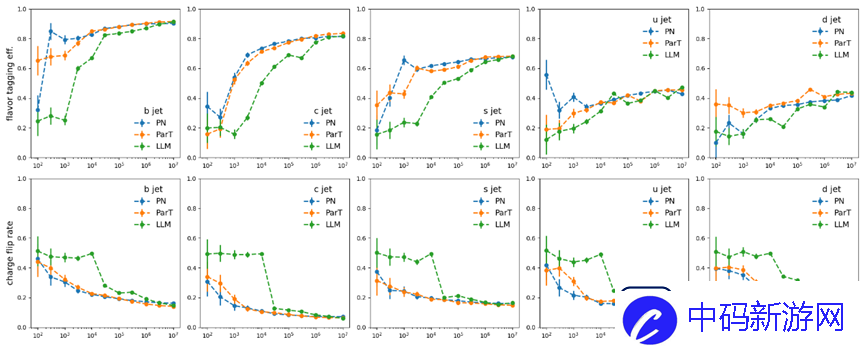
图4:喷雾香味识别准确率(上)和电荷误判率(下)与训练数据量的关系。二值分词:统一多模态数据处理,突破数值数据分析瓶颈
近年来,大型语言模型在文本处理和常识问答等任务上取得了显着进展,但在处理大规模数值数据方面仍然面临挑战。
传统的BPE分词方法在对数字进行分词时可能会引入歧义和不一致的情况。尤其是在高能物理和天文观测等领域,分析复杂的实验数据成为瓶颈。
为了让大型模型更适合科学计算场景,本研究引入了一种创新的二进制标记化方法(Binary Tokenization),利用计算机存储中使用的数据的二进制表示方式,实现数值数据与文本、图像的多模态融合等等。数据的统一表示。
这使其能够通过二进制分词实现所有数据类型的统一处理,无需额外的预处理,简化了预处理过程并保证了输入数据的一致性。
论文中,研发团队详细演示了如何克服传统BPE方法的局限性及其数据处理流程。
BPE 方法的局限性
歧义和不一致
BPE是一种基于频率的分词方法,它根据上下文将数字分割成不同的子单元,这可能会导致相同的数字在不同的上下文中被不同地分割。
例如,数字12345 在一种上下文中可能会被拆分为“12”、“34”和“5”,在另一种上下文中会被拆分为“1”、“23”和“45”。这种分割方法由于破坏了数字及其数值关系的完整性而失去了原有数值的内在意义。
令牌ID不连续
BPE 会导致数字令牌ID 不连续。例如,数字“7”和“8”的令牌ID 可能分配为4779 和5014。
这种不连续性使得管理和处理数字数据变得更加复杂,特别是当需要顺序或模式化令牌ID时,并且这种不连续性影响模型处理和分析数字数据的能力。
个位数标记化问题
尽管单位数字标记化方法简单明了,但它也会导致不连续的多位标记ID。例如,数字15 可能被分解为单独的标记“1”和“5”,每个标记都映射到单独的标记ID。
这种分割可能会破坏数值信息的连续性,使模型更难以捕捉多位数字的内在结构和关系。
数值处理方法
对于文本数据,UTF-8 编码用于将字符转换为字节序列。
对于数字数据,提供了双重策略:一种是当数字的确切格式和任何可能重要的前导零被保留时,数字被视为字符串,然后使用UTF-8 进行编码;另一种是在执行算术运算或处理重要数值时,将数字转换为其数值形式(例如整数),然后转换为字节数组。这种方法确保模型能够统一、高效地处理各种数据类型。
对于科学公式或符号:复杂的表达式被解析并序列化为字节序列,捕获公式的结构和内容。例如,公式E=mc^2 被编码为字节数组[69, 61, 109, 99, 94, 50],表示公式的结构和变量。
对于图像数据,使用patch方法将图像分解为小块,以提高高密度像素数据的处理效率。
BBT-Neutron模型架构:有效捕捉数值关系和多功能任务适应
BBT-Neutron模型架构主要由三个关键部分组成:Patch Embedding、Patch Self-Attention和LM Head。它可以通过字节分割将输入序列转换为高维向量,使其能够执行分类和回归任务。的多种能力。
这些任务在许多科学应用中非常常见,目标不一定是生成新序列,还包括对输入进行分类或预测连续值。
补丁嵌入
它由两个线性层组成,第一层将输入块投影到高维空间中,第二层细化此表示以产生最终的嵌入向量。
在两层之间引入ReLU激活函数,允许模型非线性地表达输入字节补丁并捕获补丁内字节之间更复杂的结构。与通常仅使用单层线性嵌入的字节级模型相比,它可以提供更大的灵活性并更好地表示输入补丁的细节和非线性关系。
补丁自注意力
在补丁自注意力机制中,注意力操作是在补丁级别执行的。每个补丁嵌入包含其所有点的信息,通过矩阵乘法促进不同补丁之间的信息交换,同时促进单个补丁内字节之间的交互。使模型能够有效地捕获本地和全局依赖关系。
LM头
输出维度定义为Patch Size 257,其中257表示0到255的字节值总数,加上256表示的padding ID,Patch Size是文本序列被划分成的patch的数量。这种设计允许模型独立地为每个补丁生成预测,从而保持基于补丁的方法的效率和有效性。
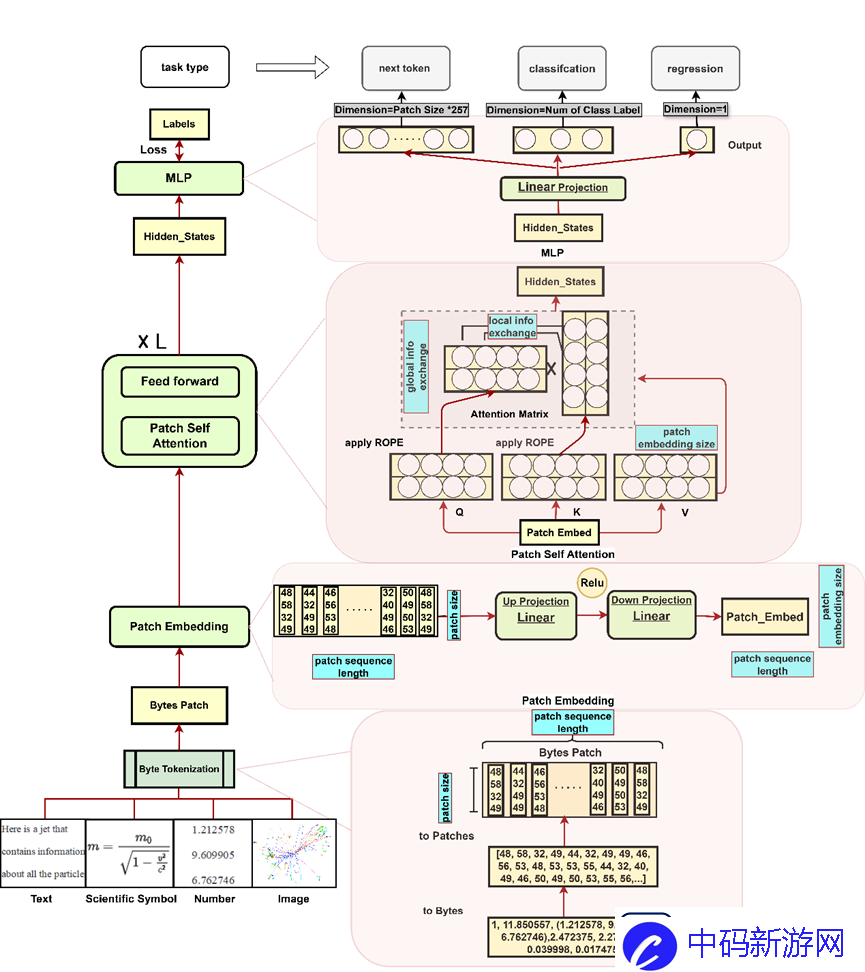
图5:应用于粒子物理碰撞数据分析的BBT-Neutron模型架构图:通用架构性能在专业领域达到SOTA
论文中,开发团队分享了首次实现BBT-Neutron通用架构协助粒子物理关键任务————喷流起源识别(JoI)的成果,并取得了突破性成果。
喷流源识别是高能物理实验的核心挑战之一,旨在区分来自不同夸克或胶子的喷流。
高能碰撞中产生的夸克或胶子立即产生粒子束——,主要是沿相同方向移动的强子——。这种粒子束通常称为射流,是碰撞实验中物理测量的关键对象。
识别喷流的起源对于许多物理分析至关重要,特别是在研究希格斯玻色子、W 和Z 玻色子时,它们几乎70% 的时间会直接衰变成两个喷流。
此外,喷射是我们理解量子色动力学(QCD,描述原子核、质子、中子和夸克相互作用机制)的基础。
来自不同类型的带颜色粒子的喷流在可观察到的数量上仅略有不同,这使得准确识别喷流的来源极具挑战性。
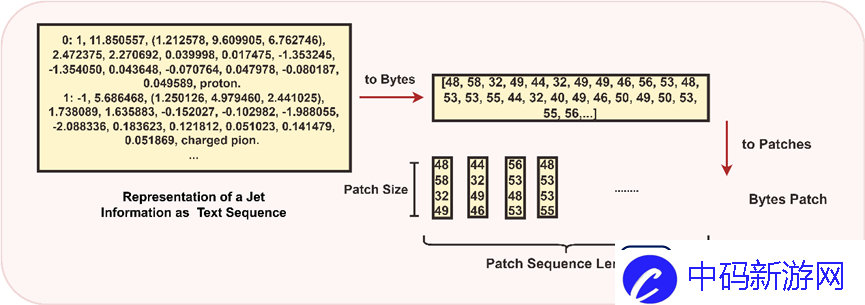
图6:带有patch的二值分词方法处理粒子物理数据流的实验结果表明,该研究与最先进的专业模型(例如Particle Transformer和ParticleNet,将专业物理定律融入到模型中)的最佳性能不相上下。 GNN架构设计),达到行业标准SOTA(图1-3)。
这一结果验证了基于序列到序列建模方法的解码器唯一通用架构在学习物质世界和物理定律方面具有与专业模型相同的学习能力。
传统概念认为seq2seq建模不适合对时间、空间、能量等具有连续特征的物理现实进行建模,而只适合对人类语言等离散符号进行建模。
而且,从左到右的位置特征的学习方法并不适合具有时空对称性的物理结构。模型要学习专业的物理定律,需要将本领域的相关结构融入到专业的模型架构中。
本文的研究成果证明了这一概念的局限性,为表示时间、空间、能量等基本物理量提供了有效的解决方案,也为物理化学等专业科学领域构建统一模型提供了基础。
尺度分析:发现突发行为
论文通过比较ParticleNet 和Particle Transformer 在JoI 任务上的缩放行为,对数据量增大时的Scaling 行为进行了深入分析。
这些训练数据集范围从100 万到1000 万个事件,实验结果通过三个关键指标来衡量:混淆矩阵、喷射风味标记效率和电荷翻转率。模型性能。
混淆矩阵(Confusion Matrix)使用11维混淆矩阵M11对每次注射进行分类,并根据最高的预测分数将其分类到相应的类别中。这些块被对角化为22 块,每个块对应一个特定的夸克物种。混淆矩阵提供了模型分类性能的全面概述,突出显示了各种注入类别中的正确和错误预测。
喷流风味标记效率定义为每个块内值总和的一半,不区分夸克和反夸克产生的喷流。
电荷翻转率定义为块中非对角线元素与块总和的比率,表示错误识别夸克和反夸克产生的喷流的概率。
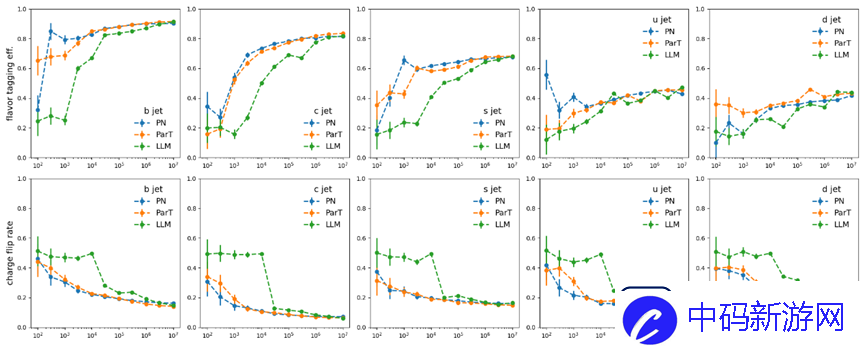
图4显示这些模型在11种粒子注入源识别的分类问题上表现出相似的性能,并且当数据集规模扩大时都表现出性能改进。喷射风味标记效率、电荷翻转率形成S曲线。开发团队指出,该模型和专业模型之间存在不同的缩放行为。 BBT-Neutron S曲线上的关键数据阈值,尤其是电荷翻转率数据,出现了性能突变,呈现出明显的涌现现象(Model Emergence)。然而,在ParticleNet 或Particle Transformer 中尚未观察到这种现象。
可能的原因是这些专门的模型结合了特定领域的结构特征,并且它们采用专门设计的架构来表示粒子相互作用和分类,这可能会导致性能改进随着数据大小的增加而更快地饱和。
相比之下,正在研究的通用架构模型使用统一的数据表示来处理所有物理结构。专业的模型架构通过消除位置编码或相关操作来实现粒子的置换不变性。 BBT-Neutron不依赖于置换不变性,而是使用从左到右的序列输入,这与语言模型的seq2seq范式一致。
虽然这种方法需要更大的数据集进行推理,但一旦超过关键数据集阈值,它就会实现显着的性能飞跃,这表明该模型甚至没有像专业模型那样在架构设计中明确纳入排列不变性。并且还可以通过足够数据的学习来学习空间对称性。
通俗地说,当数据规模逐渐增大时,模型表现出性能的显着跳跃。这一发现验证了通用模型在大规模科学计算任务中的可扩展性,即该模型有望成为跨领域的科学计算基础模型。
本文的研究标志着大型模型在多模态数据处理和科学计算任务中的巨大潜力。随着人工智能技术与大型科学装备的深度融合,未来或有可能加快中国大型对撞机CEPC等前沿科研项目的实施。
该项目参与者、CEPC团队成员阮曼琪曾评价道:“人工智能技术将辅助大型科学设施的设计和开发,极大提高其科学发现能力,更好地帮助我们探索世界的奥秘。拓宽人类知识的边界。
反过来,通过总结和比较在具体科学问题上观察到的人工智能表现的差异,我们也可以加深对人工智能技术本身的理解,更好地推动人工智能技术的发展。 ”
BBT模型发展历史
2022年:发布BBT-1,10亿参数的金融预训练语言模型;
2023年:发布BBT-2,120亿参数的通用大语言模型;
2024年:发布1.4亿参数的科学基础大语言模型BBT-Neutron,实现文本、数值、图像数据多模态统一预训练
参考:
https://arxiv.org/abs/2412.00129
相关资讯
-

三个男人换着躁我第1集:深度剖析三位男主角的独特魅力(平台:粉丝社区)
随着电视剧《三个男人换着躁我》的首播,该剧迅速引起了观众的广泛关注。故事围绕三个性格截然不同的男性角色在各种意想不到的情况下相遇, -

暴躁老外玩Minecraft中国农村冒险之旅-玩家热议:刺激与乐趣并存!
在全球范围内,《我的世界》已经成为一款现象级的沙盒游戏,吸引了无数玩家的喜爱和投资。这位脾气暴躁的外国人独特的风格和幽默感让他在游 -

-

-

-

-

-
